
CData Software Acquires Data Virtuality to Modernize Data Virtualization for the Enterprise
Data Virtuality brings enterprise data virtualization capabilities to CData, delivering highly-performant access to live data at any scale.

In the current business environment data needs to be integrated between multiple cloud-based and on premise sources. You can do this either through data replication which makes a copy of the data or through data virtualization which combines this data on request.
With the Data Virtuality Platform you no longer need to choose between the two. Our platform uniquely combines data virtualization and data replication. This gives data teams the flexibility to always choose the right method for their specific requirement. It provides high-performance real-time data integration through smarter query optimization and data historization as well as master data management through advanced ETL in a single tool.
In this blogpost series, you will
Data replication is a synonym for physical data integration. In this process, copies of new tables are created in a central storage which represent the data from the source systems in a transformed, historized or cleansed form.
There are various ways to do this. For example, data can be copied between a local source and the cloud or between two on-premises hosts or between a local host and another host in a different location.
There are five data replication types available in the Data Virtuality Platform which we will cover in our blog post series. These are
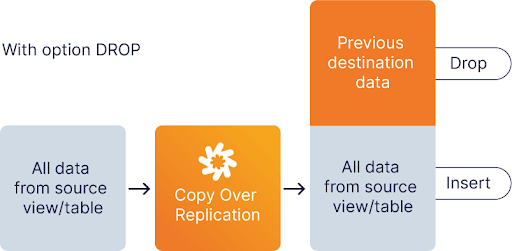
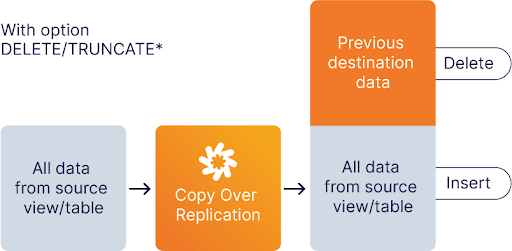
CopyOver Replication also known as Full or Complete Replication clones a table or view to the destination. The destination table can either be deleted or dropped and recreated in the process. All the data is copied over.

On the Data Virtuality Platform, the CopyOver replication method retrieves the current data from a given source and puts it into the destination table. If a table with the same name already exists, it will be handled according to the cleanup method that you selected:
The Data Virtuality Platform is trusted by businesses around the world to help them harness the power of their data. Book a demo and test all the features of the Data Virtuality Platform in a session tailored to your use case.





Data Virtuality brings enterprise data virtualization capabilities to CData, delivering highly-performant access to live data at any scale.

Discover how integrating data warehouse automation with data virtualization can lead to better managed and optimized data workflows.
Discover how our ChatGPT powered SQL AI Assistant can help Data Virtuality users boost their performance when working with data.
While caching offers certain advantages, it’s not a one-size-fits-all solution. To comprehensively meet business requirements, combining data virtualization with replication is key.
Explore the potential of Data Virtuality’s connector for Databricks, enhancing your data lakehouse experience with flexible integration.
Generative AI is an exciting new technology which is helping to democratise and accelerate data management tasks including data engineering.


