
CData Software Acquires Data Virtuality to Modernize Data Virtualization for the Enterprise
Data Virtuality brings enterprise data virtualization capabilities to CData, delivering highly-performant access to live data at any scale.

The last instalment in our series on replication. In this blog post we will tackle History Replication and its use cases. Until now we looked at CopyOver Replication, Incremental and Upsert Replication and Batch Replication.
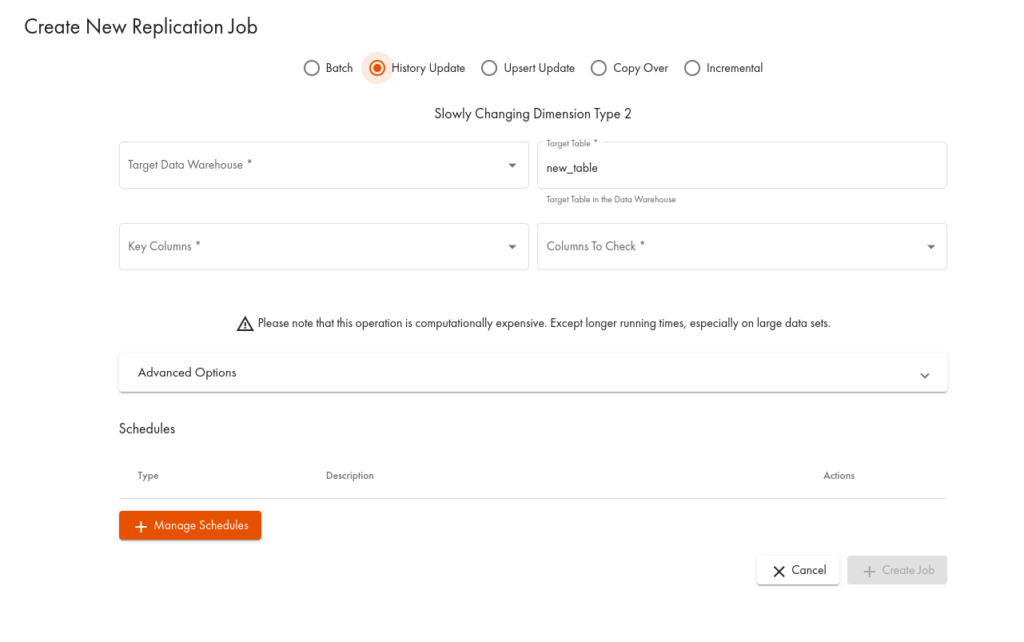
The purpose of History Replication is to historize the data changed in the source table to the destination table with added validity time frame. This replication type implements the Slowly Changing Dimensions Type 2 process known from Data Warehousing.
It is very useful in situations where we need to keep track of changes made to data, such as when you have to deal with financial transactions and need to have a clear view of all the activities involved. Or when you need to have a history of the data for security audits. . Complete, incremental, or batch replication will always yield a table which contains all available data so they aren’t really fit for situations where you need to track changes.
Incremental or batch updates may keep ‘old’ data which is not present in the data source anymore. Generally, changes of data cannot be tracked, and the user is always forced to work with the most current information.
That is why if you need to know when and how the data has been changed, history update is the right replication type to use. There are several ways to implement this type of replication.
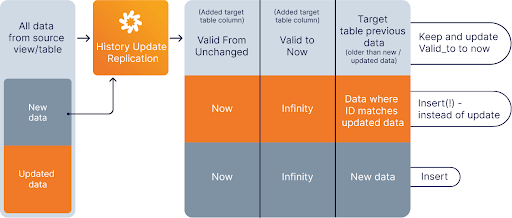
In our platform, history replication is based on performing a kind of versioning on the data records by adding two columns to the storage table where the data is replicated to. These columns, called fromtimestamp and totimestamp, provide information on the period when the given record was the current version. Here’s how this works:
The Data Virtuality Platform is trusted by businesses around the world to help them harness the power of their data. Book a demo and test all the features of the Data Virtuality Platform in a session tailored to your use case.





Data Virtuality brings enterprise data virtualization capabilities to CData, delivering highly-performant access to live data at any scale.

Discover how integrating data warehouse automation with data virtualization can lead to better managed and optimized data workflows.
Discover how our ChatGPT powered SQL AI Assistant can help Data Virtuality users boost their performance when working with data.
While caching offers certain advantages, it’s not a one-size-fits-all solution. To comprehensively meet business requirements, combining data virtualization with replication is key.
Explore the potential of Data Virtuality’s connector for Databricks, enhancing your data lakehouse experience with flexible integration.
Generative AI is an exciting new technology which is helping to democratise and accelerate data management tasks including data engineering.


