
CData Software Acquires Data Virtuality to Modernize Data Virtualization for the Enterprise
Data Virtuality brings enterprise data virtualization capabilities to CData, delivering highly-performant access to live data at any scale.

In the first blog post I gave an intro into data virtualization as well as examples of how I use it to solve some of my daily tasks. In this post I will tackle SQL Stored Procedures and the awesome things you can do with them.
Procedural SQL allows you to create sequences of instructions to manipulate, transform, read and write data. Think of it as a reusable recipe with multiple instructions to read, transform, clean, and manipulate data. While “SELECT” statements would be a single line inside the recipe.
Procedural SQL is so useful that it is implemented by the Data Virtuality Platform, Oracle, MS SQL, MySQL, IBM DB2, and many others. It is even part of the ANSI SQL standard. Database servers such as Oracle and others, implement Procedural SQL to operate on the data you have in that database. However, Data Virtuality uses Procedural SQL to operate on the data across many different servers, giving you the ability to integrate and orchestrate different systems.
TIP: When shopping for virtualization software, be sure to ask in what language you can implement Stored Procedures in. I personally like writing Stored Procedures using SQL as the single language. I don’t have to leave the IDE, I can quickly test and develop the code without leaving my tool. There are other virtualization software that allow you to write queries using SQL but then require you to create Stored Procedures in Java. This can be a bit cumbersome since you need a separate Java IDE and Java developer skills to do it. So be sure to ask and verify you don’t need to learn or know several programming languages just to automate your tasks.
Some of our clients have built some amazing things using Stored Procedures in Advanced Data Virtualization. One company uses Stored Procedures to automate the onboarding of new clients. The Stored Procedures create the new data sources, create a new schema, create tailored views for this new client, set permissions, and run automated tests to verify the correctness of the new views.
Another client uses Stored Procedures for automating the creation of Stored Procedures. It’s pretty impressive. They use Adobe Analytics and routinely need to create requests using many combinations of metrics and elements. With a single call they can create a whole new Stored Procedure with custom parameters and a custom result set.
Many clients use Stored Procedures to update their data lakes. They use virtualization to read the data, then write the data to disk as a Parquet file. Finally moving that file to S3 or Azure Blob storage. Once the data is in the cloud, they load it into a server for processing.
I used Stored Procedures to convert data to HTML tables. I call the Stored Procedure with the name of the table or view. The Stored Procedure takes the data and converts it into HTML. The Stored Procedure then embeds the HTML table in the email and sends it to the lists of recipients.
I also use Stored Procedures to implement functions from other SQL dialects. I implemented DB2’s TRANSLATE function using SQL. You can find more information here about DB2’s TRANSLATE function https://www.ibm.com/docs/fi/db2-for-zos/11?topic=functions-translate
Another coworker implemented the MS SQL function ENDOFMONTH using Data Virtuality. You can find the code here: https://support.datavirtuality.com/hc/en-us/articles/201088509-MSSQL-ENDOFMONTH-Replacement
Stored procedures can optionally return data and can be used in queries as if they were tables (incredibly handy). They can accept parameters. They can return a single row or many rows of data.
This stored procedure CopyDataToS3 does not return data and it does not accept parameters. But it does call two other stored procedures: getFiles and saveFile using the keyword call.
CREATE PROCEDURE views.CopyDataToS3()
as
BEGIN
/*The first step retrieves the file data as a BLOB object*/
DECLARE BLOB raw_file = SELECT file FROM (
call "parquet_files.getFiles"("pathAndPattern" =>
'*.parquet'))a;
/*The second step takes the BLOB object and saves it to a
bucket or folder on S3*/
call "S3.saveFile"(
"filePath" => 'parquet-uploads/message_test.parquet',
"file" => raw_file
);
END;;
The stored procedure calls getFiles and returns a table with multiple rows and columns. The call is made from a SQL SELECT statement as if the stored procedure was a table and the value from the column file is stored in the variable raw_file and is then written to disk using the stored procedure saveFile.
What have we learned so far?
The stored procedure below returns data by using the RETURNS (xdate date)syntax. The RETURNS syntax defines the structure of the table that will be returned. In this example it returns a single column (it could return more). The stored procedure dateaxis accepts two parameters: startdate and enddate.
CREATE PROCEDURE views.dateaxis(startdate date, enddate date)
RETURNS (xdate date)
AS
BEGIN
DECLARE date idate;
idate=startdate;
CREATE LOCAL TEMPORARY TABLE #x(xdate date);
WHILE (idate<=enddate)
BEGIN
INSERT INTO #x(xdate) VALUES (idate);
idate=timestampadd(SQL_TSI_DAY,1,idate);
END
SELECT * from #x;
END;;
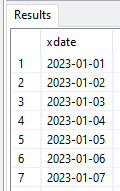
The stored procedure above returns the dates from startdate to enddate. Let’s look an example:
select * from (call "demos.dateaxis"(
"startdate" => {d '2023-01-01'},
"enddate" => {d '2023-01-07'})) as a;;
What have we learned?
The Data Virtuality Platform is trusted by businesses around the world to help them harness the power of their data. Book a demo and test all the features of the Data Virtuality Platform in a session tailored to your use case – SaaS or on-premise.





Data Virtuality brings enterprise data virtualization capabilities to CData, delivering highly-performant access to live data at any scale.

Discover how integrating data warehouse automation with data virtualization can lead to better managed and optimized data workflows.
Discover how our ChatGPT powered SQL AI Assistant can help Data Virtuality users boost their performance when working with data.
While caching offers certain advantages, it’s not a one-size-fits-all solution. To comprehensively meet business requirements, combining data virtualization with replication is key.
Explore the potential of Data Virtuality’s connector for Databricks, enhancing your data lakehouse experience with flexible integration.
Generative AI is an exciting new technology which is helping to democratise and accelerate data management tasks including data engineering.


