
CData Software Acquires Data Virtuality to Modernize Data Virtualization for the Enterprise
Data Virtuality brings enterprise data virtualization capabilities to CData, delivering highly-performant access to live data at any scale.

Did you already hear the news? We recently released the latest version of our revolutionary data integration solution, the Data Virtuality Logical Data Warehouse (LDW) 2.1! The LDW 2.1 comes fully equipped with a range of exciting new capabilities and significant advancements that enable you to integrate and model all your data with unprecedented flexibility and scalability – even in the most demanding big data environment.
To kick it off, let’s have a look at the brand-new Data Virtuality Web, our one-stop data shop for business users and applications.
With huge amounts of data now being generated and integrated on a daily basis, data management is becoming more and more complex. To make things even more complicated, your business users expect speedy and comprehensive analytical data access without so much as having to approach the IT department for support. The solution to this problem? Our state-of-the-art Data Virtuality Web client! With our DV Web we provide self-service agility and freedom while your IT can enforce security and governance rules. Simply explore and query the data that is available on the server, combine data in the BI tool of your choice, and create self-service reports – without worrying about the underlying IT infrastructure. Take data management to the next level, with Data Virtuality Web!
Data Virtuality Web is an out-of-the-box feature in LDW 2.1. That means it comes at no extra cost and you do not have to implement it manually. The only setup requirement is to update your Data Virtuality Logical Data Warehouse to 2.1 (contact us for more information). Once the update is finished, you can log into DV Web with your Data Virtuality credentials and get started. DV Web has an easy-to-use interface for business-oriented users that bridges the gap between technological complexity and data consumers by separating the logical and business data layer. In other words, DV Web simplifies and accelerates the access to the information your business users require and exposes the data in a business-friendly manner.
The DV Web client enables all business users (depending on their permissions) to search metadata and query SQL from the web browser without using the DV Studio.
The interface of DV Web is divided into four sections: Browse, Samples, Functions and Metadata Search. Here’s a detailed look at each functionality:
Our Data Virtuality Web gives business users full self-service freedom in their data discovery and exploration process. Browse and navigate through a preview of all metadata available in the data delivery layer and get in-depth information on your data that a frontend BI tool alone can’t provide. You can browse all data sets that are connected to your target source, such as schemata, tables, procedures, views of data, comments etc. If you want to look at the data directly, simply generate the respective SQL command from the table and execute it. In addition, you can download all tables generated from the available datasets as .cvs files for final consumption e.g. in Excel.
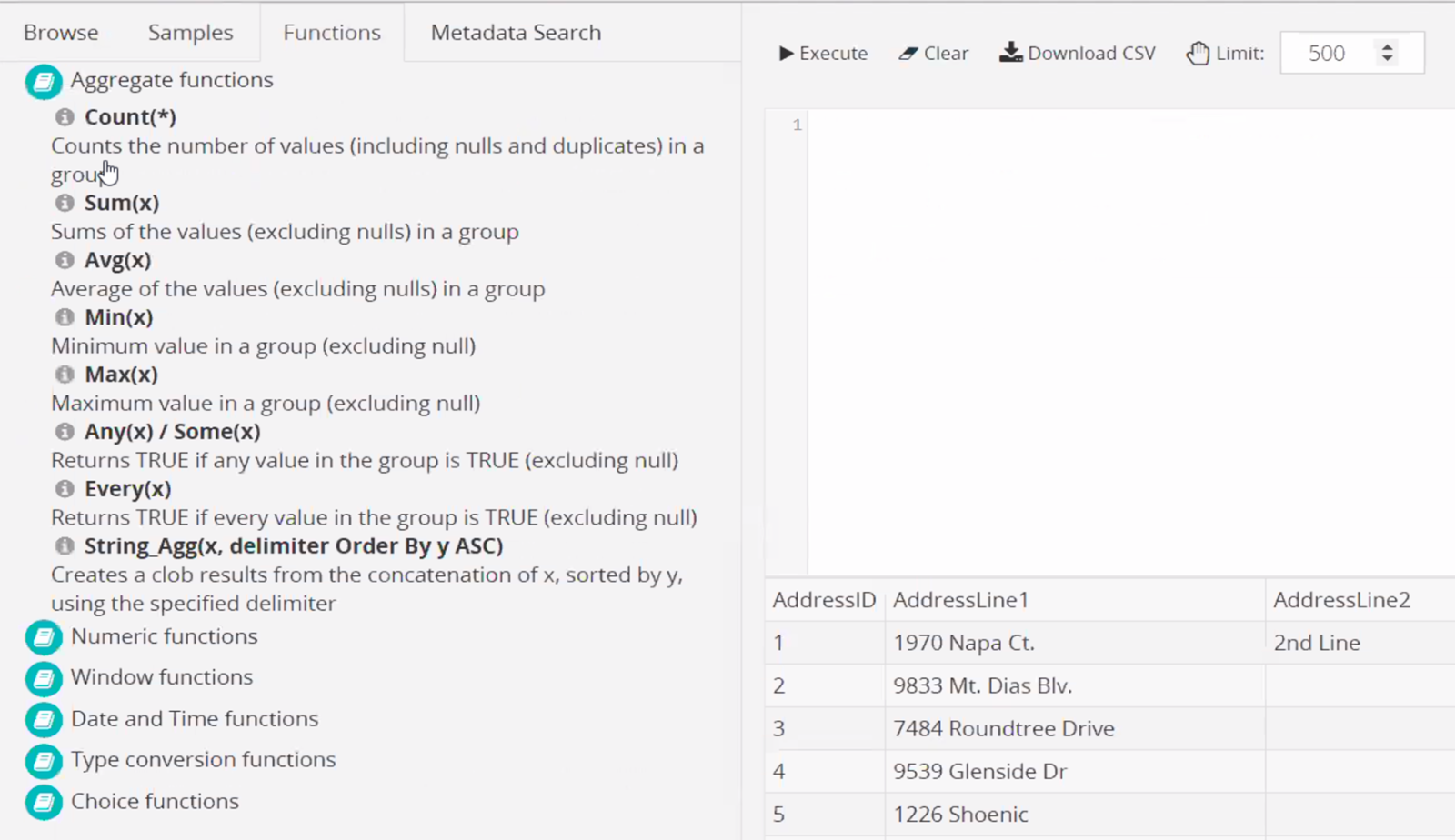
These two are relatively straight forward: You can find here a range of sample procedures as well as a collection of template functions. Use them as reference for optimized metadata querying and browsing!
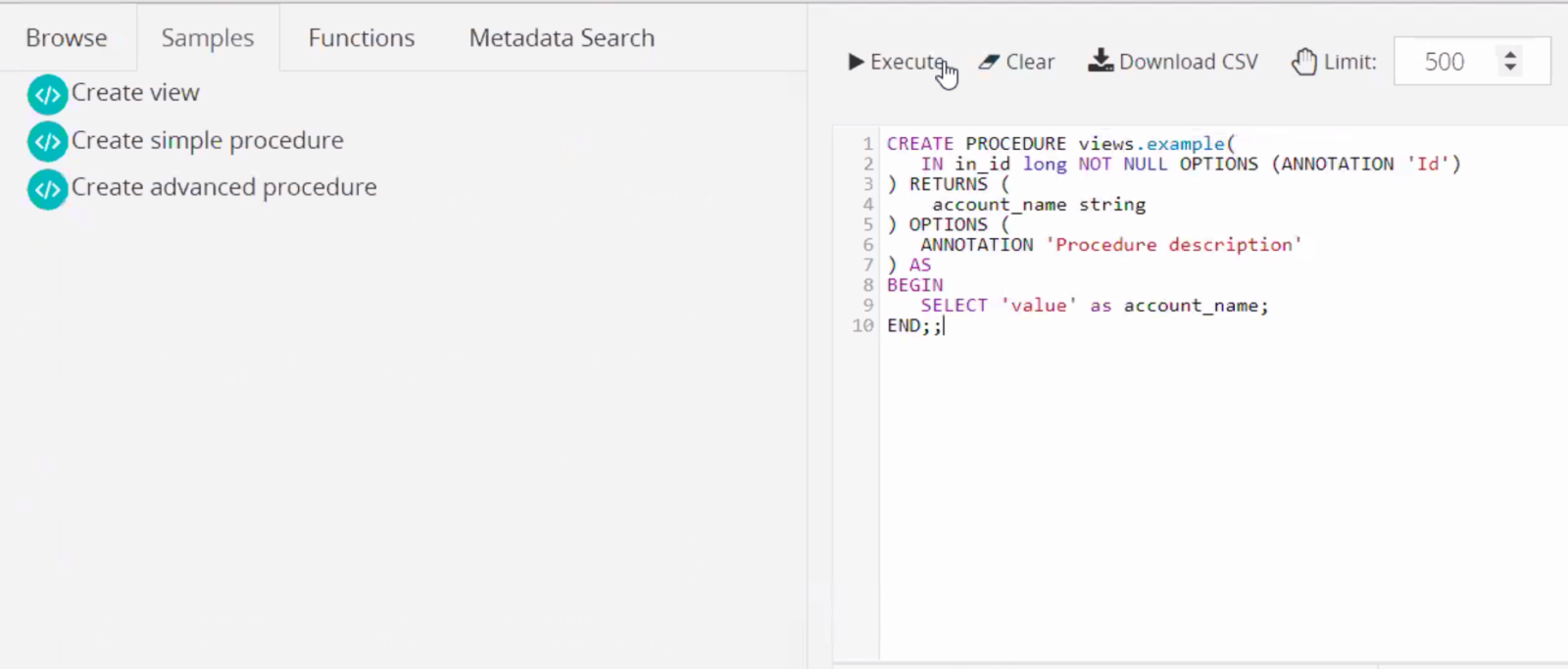
Our Data Virtuality Web gives business users full self-service freedom in their data discovery and exploration process. Browse and navigate through a preview of all metadata available in the data delivery layer and get in-depth information on your data that a frontend BI tool alone can’t provide. You can browse all data sets that are connected to your target source, such as schemata, tables, procedures, views of data, comments etc. If you want to look at the data directly, simply generate the respective SQL command from the table and execute it. In addition, you can download all tables generated from the available datasets as .cvs files for final consumption e.g. in Excel.

Leverage the powerful searching and browsing capabilities of the DV Web to get access not only to metadata but also to the actual data. View the data you need in real time and create reports with the agility and freedom of a self-service tool. And all that without having to know anything about complex SQL constructs! Indeed, you do not have to worry about the technical complexities of your data integration solution at all. They are hidden behind a business user-friendly web-based interface. You can simply start working with your data! With the DV Web, the LDW 2.1 creates a one-stop data-shop that empowers all data consumers, from analysts to business users and decision makers, to find and use information assets quickly, which is essential in today’s self-service world.
Now, this time we put the focus on the technical users, meaning your IT, BI developers, and data engineers. Or, in other words, those who are in charge of the construction and administration of the business data models.
At Data Virtuality, we know how essential the work of the IT department is for the success of every data integration project. So, we wanted to do more to support them in their workflows. And with this, we proudly present to you the second new key feature of our Logical Data Warehouse 2.1, the Data Virtuality Synchronization Tool, or DV Sync Tool for short.
But let’s start from the beginning!
Your c-level has tasked the BI Analysts of the company to prepare a new business report that shows the total sales by customer country per quarter. So, your BI developers go through the data model to check which reportings already exist. They find reportings for total sales, for total sales per quarter – but there’s no reporting for total sales per customer country yet. That means parts of the data model need to be edited, new views/dimensions need to be added, etc. In short, the production environment of your data integration system needs to be adjusted to accommodate the task requirements and deliver the specific reporting your BI Analysts needs.
And this is where the true challenge begins!
Many data models in data integration tools only have one instance or environment on which all productive reportings and corresponding automatizations run, and which is being accessed by all frontends. If you now want to change the existing data model structures to get your business report, you will have to change them directly in the production instance. While all your other reportings are running and without being able to test the changes before implementing them. In short, it’s a disaster waiting to happen!
Indeed, whether it hampers the performance of your reportings or outright cripples the entire process – having only one instance for staging and production can put your entire system at risk. And let’s not even speak about all the other business operations that depend on your data model running smoothly.
Of course, this poses a serious dilemma: How can you edit your data model if it only has one instance?
Some ingenious users may come up with an apparent quick fix – they simply duplicate the views that need to be changed! By doing so, they get two environments, one for production, and a copy that acts as staging/development instance. Once all changes have been tested and implemented successfully, the dev instance is simply re-named and thus turned into the new production instance.
Sounds like a solid plan? Not quite!
This quick fix may work for smaller projects or companies whose data models aren’t that large. But it’s not feasible in an enterprise environment or for projects with lots of interdependent views and jobs. Because, at some point, it simply becomes impossible to keep track of all the duplicated views, each of which supplies several jobs. They, in turn, reference a couple of more views. And those are also not isolated … and so on. You’d end up with a hodgepodge of job and view copies and no way to untangle this mess.
Also, larger companies and enterprises usually follow very strict review processes and approval loops which are by design incompatible with this kind of improvised solution.
So, it’s back to square one – or isn’t it?
Don’t waste your time with risky experiments on the production instance or messy duplications of the entire data model! With its Sync Tool, our Logical Data Warehouse 2.1 establishes a clear distinction between production operations and development/staging. So you can edit your data model smoothly and hassle-free whenever necessary.
Like the DV Web client, the Sync Tool is an out-of-the-box feature in the Logical Data Warehouse 2.1. All you have to do is update to the latest version of the LDW (get in touch for more information), log in with your Data Virtuality credentials, and get started.
In Logical Data Warehouse 2.1, you can install your data model on two (or more) instances. A production environment with all virtual schemas, data sources etc., and a development/staging instance which is an exact copy of the former. This allows for greater flexibility and freedom to experiment, as the staging instance acts as a stopping point before any changes touch production. So your IT can edit and safely test the data model without having to worry that their changes might interfere with the reporting and other running processes.
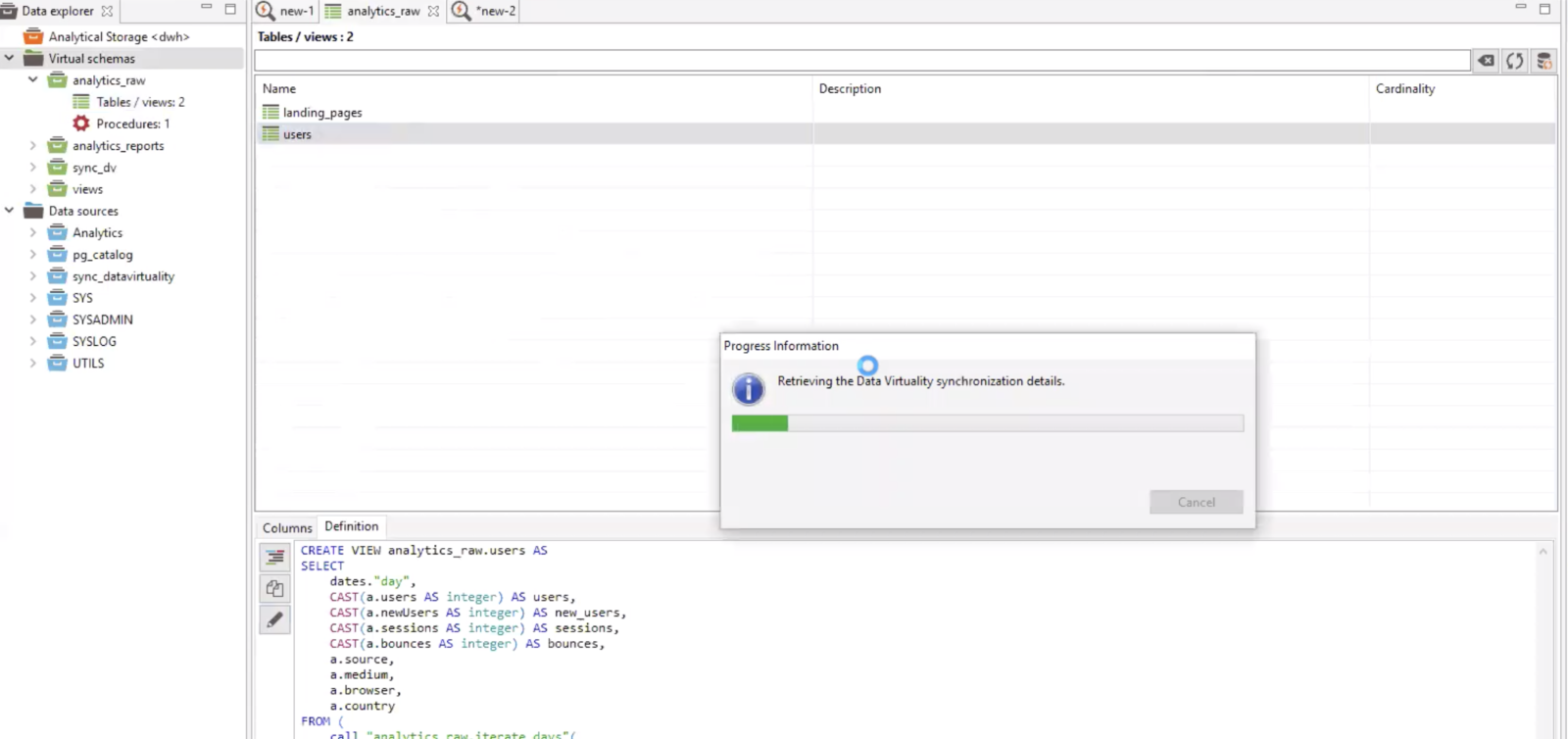
The two instances are still linked, of course. And it is at this intersection that the DV Sync Tool comes into the picture.
The Data Virtuality Sync Tool synchronizes data model changes between multiple LDW instances (staging/development and production).
Through the link between the staging and production instances, the Sync Tool automatically monitors and records all changes that have been made on the development side. They’re then shown in a list with specific icons demarcating the different types of changes, such as a plus symbol for added views or a pencil symbol for edited virtual schemas etc. In this way, you never lose track of the changes to your data model again, no matter how many jobs, schemas, and optimizations you’ve been working on.
From the list, you can select all or individual changes that you want to implement on the production instance. When you’re ready, simply click “finish”, then “synchronize”, and the selected changes are loaded automatically from the development/staging instance to the production environment where they will go live immediately. If you call up the production instance you will be shown the most recent changes/differences between the two environments. Nothing breaks, nothing gets lost, everyone’s happy!
And did we mention that with the LDW 2.1 it’s also possible to have more than two instances? This is especially interesting for enterprises whose processes for changing/editing data models usually have several stages (e.g. development, QA testing, and approval) before any changes are pushed live.
And the synchronization also works the other way around, meaning you can transfer jobs and views that have been active on the production environment to the staging instance for adjustments.


BI projects are always in motion and new reportings have to be added all the time. So your developers are permanently tinkering, adjusting, developing to make sure that the data model can accommodate every use case your team is getting tasked with. In order to work efficiently and flexible, they need the right tool in place that can support them every step of the way.
With the DV Sync Tool, the LDW 2.1 has introduced a valuable feature that enables you to optimize and edit as many jobs and schemata as you need on the staging instance, and have them automatically synchronized with and released on the production instance once you’re finished.
Make messy duplications and risky changes in the production instance a thing of the past, and take your data management to the next level.
But what are Modular Connectors? How do they work? And, most importantly, how do you get them?
Modular Connectors are smart, easy-to-deploy connectors that contain both business logic as well as replication logic. Modular Connectors provide templates that cover most of the use cases working with APIs. With Modular Connectors you can:
Last question first: To get the Modular Connectors, you first need to get the newest version (2.1) of our Data Virtuality Logical Data Warehouse. Once you have the LDW 2.1 installed, you can find a list of connectors that are available as Modular Connectors in your DV Studio.
And with these three simple steps, you’re good to go!
For a full list of all modular connectors to choose from just contact us at support@datavirtuality.com.
Our Modular Connectors come with smart, in-built templates which contain the prepackaged logic of how to extract meaningful data from different data sources in little to no time.
All you have to do is choose the templates you need and specify at which time they have to be loaded. The system will then automatically load the data into the database and incrementally replicate it.
The result: you get all the data you need with the respective meta descriptions in just a few clicks. No manual querying or writing clunky SQL scripts required! Querying data has never been easier!
Book a demo and test the features of the Data Virtuality Logical Data Warehouse 2.1





Data Virtuality brings enterprise data virtualization capabilities to CData, delivering highly-performant access to live data at any scale.

Discover how integrating data warehouse automation with data virtualization can lead to better managed and optimized data workflows.
Discover how our ChatGPT powered SQL AI Assistant can help Data Virtuality users boost their performance when working with data.
While caching offers certain advantages, it’s not a one-size-fits-all solution. To comprehensively meet business requirements, combining data virtualization with replication is key.
Explore the potential of Data Virtuality’s connector for Databricks, enhancing your data lakehouse experience with flexible integration.
Generative AI is an exciting new technology which is helping to democratise and accelerate data management tasks including data engineering.


