
CData Software Acquires Data Virtuality to Modernize Data Virtualization for the Enterprise
Data Virtuality brings enterprise data virtualization capabilities to CData, delivering highly-performant access to live data at any scale.

In the last few years, we have seen the emergence of a new approach to data engineering called Data Mesh. This emerged primarily because of the increasing abundance of new data sources available to business and an increase in demand from business departments who want to analyse clean, integrated data from these different data sources. The problem is that IT professionals, who have traditionally done data engineering for the business, have become a bottleneck and can’t keep pace with demand. Data Mesh emerged in 2019. It is a decentralised data engineering approach based on four major principles:
The idea is that business domain subject matter experts use self-service tools to create pipelines that produce ‘data products’. Data products are reusable data sets that can be consumed by different analytical systems in support of different analytical workloads. For example, in Insurance some examples of data products would be customers, brokers, products, agreements, premium payments, claims etc.
Each business domain creates and owns data products that can be published, shared, and consumed elsewhere in the enterprise to help shorten time to value. This has given rise to two roles. These are data producers and data consumers. The data mesh approach is that data products are created by different teams of data producers in different business domains who intimately know, understand, and use specific data on a daily basis. Each team of data producers is tasked with:
The above process can be shown in Figure 1. Here you can see the different data products defined in the business glossary of a data catalog, and the corresponding data integration pipeline to produce each data product and publish it in a data marketplace.
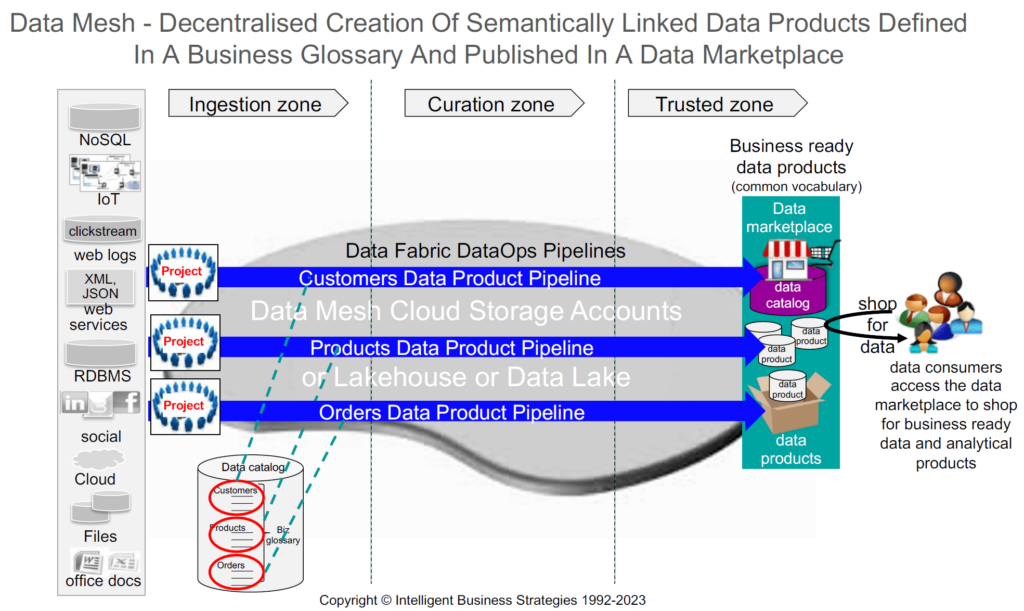
Data Mesh is therefore a collection of data products, and the data marketplace is the mechanism by which data products can be published and shared in a governed manner. Note also, that data products can be consumed and integrated with other data to create new data products that can then also be published in the data marketplace. Over time the data mesh grows so that more and more read-made data is available for use. That should mean that consumers benefit because even more of what they need should be available to them ready-made which should in turn mean that they can deliver value faster.
Data marketplaces can also be used as a shop window to gain access to external data from inside the enterprise. Many companies these days, buy in data from a range of external data providers. For example, financial markets data is available from data providers such as Bloomberg, and Standard and Poors. The problem is that different parts of a business often buy data from different and sometimes the same suppliers. They may also use different mechanisms to ingest that data (e.g., APIs, secure FTP, etc.) from each individual external data provider, load it into their own data stores and integrate it with their own internal data. This makes it much harder to govern. A much more robust way of governing this is to provide access to external data from a range of external data providers using an internal data marketplace. This creates a single place for everyone to get access to up-to-date external data sets. It also allows the data to be ingested once or remain where it is in the external data providers and to be made available without the need to copy it via virtual views published in the data marketplace.
With this approach all the agreements with external data providers can be controlled centrally by your organisation’s procurement department and shared in a compliant manner via an enterprise data marketplace. All the consumer has to do is shop for the data they need in the data marketplace, join the external data to their own internal data to create enriched data that yields better insights for competitive advantage. This use of a data marketplace opens up a governed external data supply chain within the enterprise and makes it easy for consumers to get at the value-added data they need.
One way in which data products can be produced is using data virtualisation software. In this context, perhaps a better name is virtual data products. Figure 2 below shows how this can be done using an insurance example.
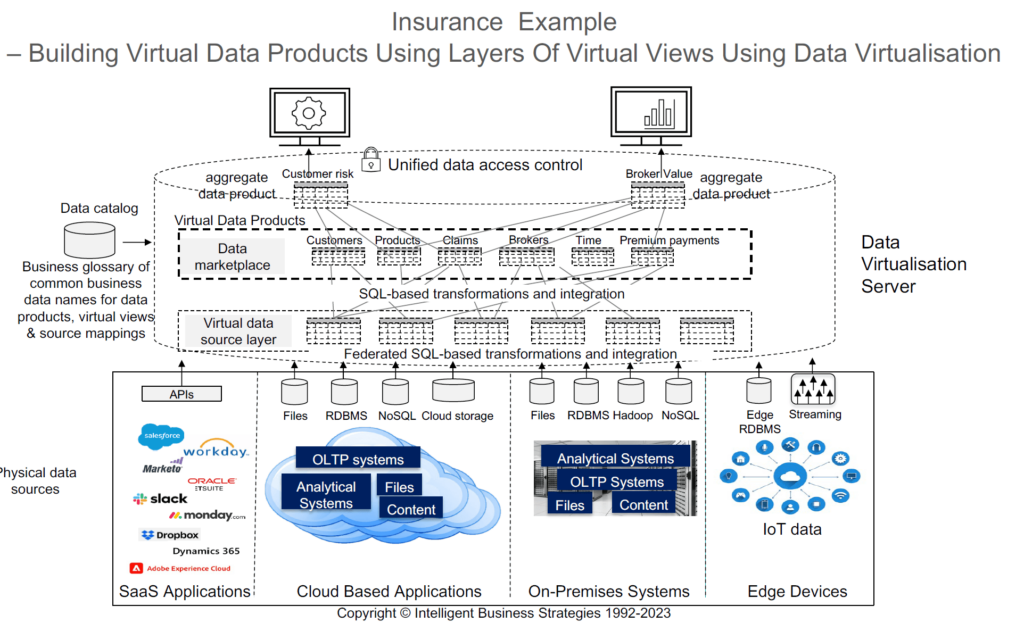
The data virtualisation server can connect to a range of data sources. Virtual views can be created, and mappings defined to map source data to columns in the virtual views. Federated queries can then integrate the source data on-demand. You can then create virtual views on top of source views and use SQL to transform data to create the required virtual data products. Note that some data virtualisation servers (such as Data Virtuality) can materialise those virtual data products if required by writing them to a relational DBMS. This is an often-overlooked point which means that ETL capability is possible. Frequently accessed data can also be cached.
Having defined the virtual data products, they need to be published to a data marketplace. Data Virtuality is an example of a data virtualisation vendor that provides the ability to create virtual data products and that also has a data marketplace capability for exactly this purpose. It is called the Business Data Shop and is shown in the Figure 3 screenshot.
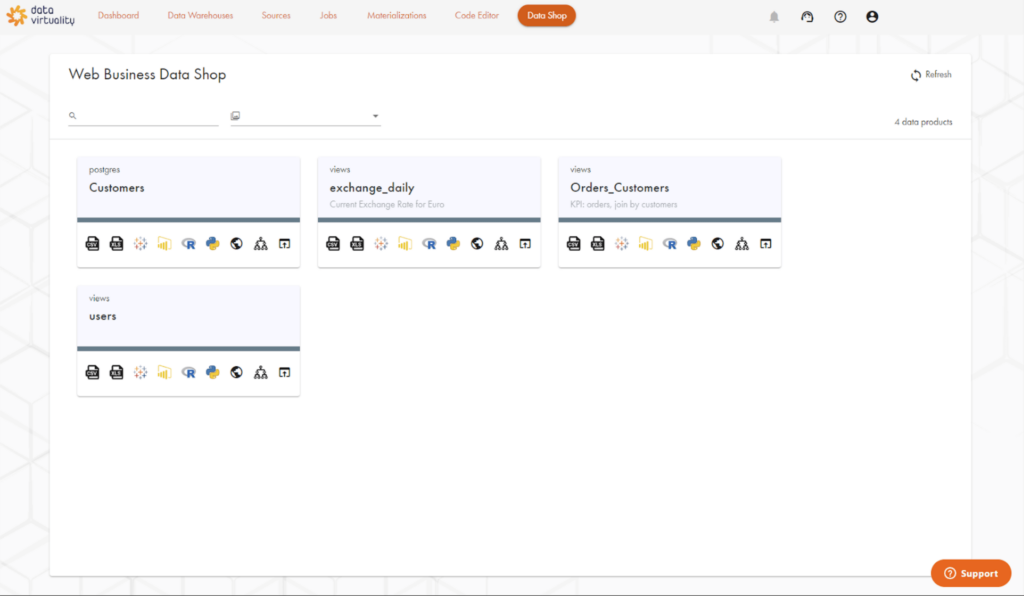
Data Virtuality allows data producers to create virtual views as data products and publish them to the Business Data Shop within the data virtualisation server where they can be made available to consumers via a number of interfaces. These interfaces can be seen directly underneath each data product in Figure 3 and are all available via a single click. Data consumers can find the data products they need in the data shop and click to preview the data in either Excel or CSV format. It is also possible to open and view data products directly in a BI tool like Tableau or Microsoft Power BI, and the Business Data Shop provides data scientists with auto-generated Python and R code to enable them to access data products directly from their Python notebook or RStudio notebook respectively. It also provides auto-generated code to access the data in the data product via an HTTP request. All of these options are available via a single click. Also, data is not copied, which makes it easier to govern and avoids data redundancy. It provides consumers with visual lineage so that they can see and understand how each data product was produced. Finally, data owners can govern access to data products to ensure that data sharing is correctly governed.
It is this kind of functionality that allows data virtualisation software to be used in Data Mesh implementation. Data products can be created by different domain-oriented teams of data producers in a similar way to that shown in Figure 2 and then published in a data marketplace for access and use by data consumers via a variety of interfaces. The idea is to build data products once and reuse them everywhere in a secure manner to support multiple analytical workloads. For example, to support business intelligence users, data scientists and other consumers. Embracing this approach not only streamlines the data consumption process but also empowers teams across different domains to collaborate seamlessly, driving better decisions and insights.
Watch the recording of our webinar with Mike Ferguson, CEO of Intelligent Business Strategies, originally aired on September 26! Dive into the complexities of current market trends, including data fabric and data mesh, and discover how AI-enhanced tools are streamlining data integration in today’s fast-paced environment.
Don’t miss this chance to gain invaluable insights and empower your organization for a data-driven future.

About the author
Mike Ferguson, an accomplished independent analyst, and thought leader excels in Business Analytics, ML, Big Data, Data Management, and Intelligent Business. Recognized for his expertise in integrating BI/ML/AI to achieve real-time business optimization. As chairman of Big Data LDN and a member of EDM Council CDMC Executive Advisory Board, he’s a prominent figure in the industry.





Data Virtuality brings enterprise data virtualization capabilities to CData, delivering highly-performant access to live data at any scale.

Discover how integrating data warehouse automation with data virtualization can lead to better managed and optimized data workflows.
Discover how our ChatGPT powered SQL AI Assistant can help Data Virtuality users boost their performance when working with data.
While caching offers certain advantages, it’s not a one-size-fits-all solution. To comprehensively meet business requirements, combining data virtualization with replication is key.
Explore the potential of Data Virtuality’s connector for Databricks, enhancing your data lakehouse experience with flexible integration.
Generative AI is an exciting new technology which is helping to democratise and accelerate data management tasks including data engineering.


