
CData Software Acquires Data Virtuality to Modernize Data Virtualization for the Enterprise
Data Virtuality brings enterprise data virtualization capabilities to CData, delivering highly-performant access to live data at any scale.

Data virtualization enables businesses to access, manage, integrate and aggregate data from disparate sources independent from its physical location or format in real-time.
According to DAMA, creators of the Data Management Body of Knowledge (DMBOK), data virtualization is defined as the following:
“Data Virtualization enables distributed databases, as well as multiple heterogeneous data stores, to be accessed and viewed as a single database.
Rather than physically performing ETL on data with transformation engines, Data Virtualization servers perform data extract, transform and integrate virtually.”
Organizations recognize that to make smarter decisions, delight their customers, and outcompete their rivals, they need to exploit their data assets more effectively.
This trend towards data-driven business is nothing new, but given the impact of Covid-19, the pace of transformation has dramatically increased.
“Boards of directors and CEOs believe data and analytics is a game-changing technology to emerge from the COVID-19 crisis and place it as their No. 1 priority for 2021.”
– Gartner, Top Priorities for IT: Leadership Vision for 2021
Exploiting the power of data analytics/business intelligence and workflow automation is one way for companies to accelerate new revenue streams while reducing costs by streamlining and improving the performance of data services.
But here lies the challenge – enterprise data is stored in disparate locations with rapidly evolving formats such as:
The demand for faster and higher volumes of increasingly complex data leads to further challenges such as:
To address these challenges, organizations recognize the need to move from silos of disparate data and isolated technologies to a business-focused strategy where data and analytics are simply a part of everyday working life for business users.
“Data and Analytics is no longer simply about dashboards and reports, it’s about augmenting decision making across the business.”
– Gartner, Top Priorities for IT: Leadership Vision for 2021
Data virtualization (DV) overcomes these challenges by exploiting the full potential of enterprise data. It breaks free from the requirement of knowing every technical detail of the data and ultimately aggregating data into one single ‘view’, without the need to move data into a central storage.
While all data remains in the source systems, data virtualization creates a virtual/logical layer that delivers real-time data access with the possibility to manipulate and transform the data in virtual views. This virtual layer delivers a simpler and more time-efficient data management approach.
DV tools can make data accessible with SQL, REST, or other common data query methods, regardless of source format, further simplifying data management efforts.
As a result of these innovations, Forrester and Gartner confirm that data virtualization has become a critical data strategy enabler for any enterprise looking to exploit their data more effectively.
“Through 2022, 60% of all organizations will implement data virtualization as one key delivery style in their data integration architecture.”
Gartner Market Guide for Data Virtualization, November 16, 2018
The centerpiece of a data virtualization application is the so called virtual or semantic layer, which enables data or business users to manipulate, join and calculate data independently from its source format and physical location, regardless of its cloud or on-premise storage.
While all connected data sources and associated metadata appear in one single user interface, the virtual layer allows the user to further organize their data in different virtual schemas and virtual views.
Users can easily enrich the raw data from the source systems with simple business logic and prepare the data for analytics, reporting and automation processes.
Several data virtualization products extend this virtual layer with data governance and metadata exploration capabilities, although this functionality is not included in every tool.
With sophisticated user based permission management, the virtual layer creates a single source of truth across the whole organization in a fully compliant and secure manner.
Authorized users can now access the data they need from one single point in one tool, helping to eliminate further data silos and simplify the data architecture.
Data virtualization does not normally persist the source system data, which is in contrast to simple data store replication such as traditional ETL tools.
See the later ETL chapter for more details on ETL vs Data Virtualization.
Instead, data virtualization stores metadata to feed the virtual views and enable the creation of integration logic that helps deliver integrated source system data, in real-time, to any front-end applications such as:
Using data virtualization for integrating business data from disparate sources brings a number of benefits:
Data Virtualization platforms deliver many benefits over traditional data solutions.
However, there are certain constraints that need to be considered when designing your solution:
A data mart provides an aggregated view of data, typically extracted from a traditional data warehouse.
Data Virtualization makes it easy to create a virtual data mart for expediency.
By combining an organization’s primary data infrastructure with auxiliary data sources relevant to specific, data-driven, business units, initiatives can move forward more quickly than if data would need to be on-boarded to a traditional data warehouse.
Modern agile businesses like to experience with new business ideas and models – mostly backed up by data to both implement the initiative and to measure the success. Therefore, a flexible system is needed to test, adjust and implement new ideas.
With the Logical Data Warehouse, the data virtualization component can be used for quick setup, faster iteration and data materialization capabilities to easily move data to production as required.
The built-in recommendation engine analyzes the usage of the prototype data and makes suggestions on how to optimally store the data for production use, including automatic database index creation and other optimizations.
Organizations recognize that to make smarter decisions, delight their customers and outcompete their rivals, they need to exploit their data assets more effectively.
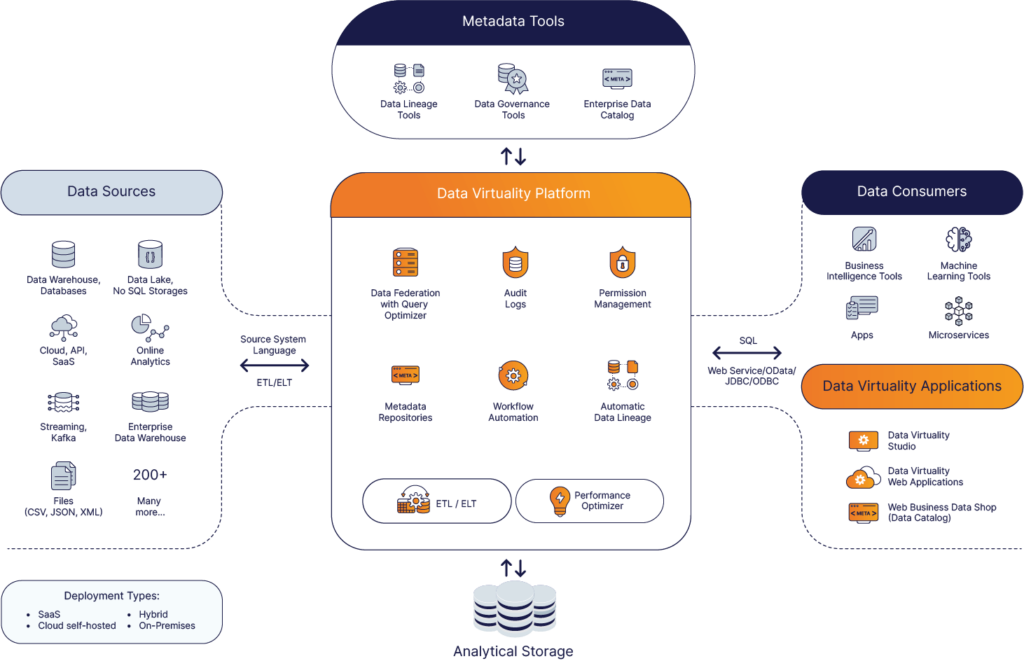
Data Virtuality is a data integration platform for instant data access, easy data centralization and enterprise data governance.
The Data Virtuality Platform combines the two distinct technologies, data virtualization and data replication, for a high-performance architecture and flexible data delivery.
IBM Cloud Pak for Data, formerly known as IBM Cloud Private for Data, is a data and AI platform that helps to collect, organize and analyze data, while utilizing data virtualization.
Denodo offers a data virtualization platform with an associated data catalog feature, enabling users to not just combine but also identify and structure existing data.
Informatica PowerCenter is an enterprise data integration platform with features such as archiving data out of older applications or an impact analysis to examine structural changes before implementation.
TIBCO’s data virtualization product contains a business data directory to help users with analyses and a built-in transformation engine for unstructured data sources.
With ETL, data is extracted from one or more source systems or data feeds, transformed using a variety of rules and logic, before being replicated and loaded into the target storage.
This type of data integration is ideal for bulk movement of data and migrating data from legacy systems to a new target application or storage structure.
A classic example of enterprise data architecture would use ETL to move data from different sources to the data warehouse.
ETL increasingly struggles to meet the speed and flexibility demands of the modern business, particularly with the rise in cloud data platforms.
Real-time data access is impossible with ETL, but preparing and moving data into a data warehouse slows down the end-to-end data delivery process, creating outdated information before it can be used for analysis and reporting.
Move large amounts of data
Large data sets need special performance optimizations for loading and processing which is provided by ETL. The ETL jobs built in a typical data warehouse environment are a great way to move large amounts of data in a batch-oriented manner. ETL tools, furthermore, simplify complex transformations and assist with data analysis, string manipulation, data changes, and integration of multiple data sets.
Advanced transformation, historization, and cleansing possibilities
Most data integration projects, especially the modern ones require data historization, batch data import and, and complex multi-step data transformation which can only be enabled by ETL. For example, matching and cleansing customer address sets from two different source systems is a challenge of typical data integration work which requires data storage and transformation capabilities of ETL.
Data virtualization (DV) is architecturally different from ETL which results in some clear differences in performance and approach:
The ideal solution is to combine these technologies. Modern data platforms take this into account.
Modern data architectures help data-driven organizations to quickly adapt to the ever changing business needs by dealing with the increasing complexity of the data landscape, enabling a growing number of diverse use cases, and ensuring flexibility and agility.
In most of today’s cases, data comes from many different places and needs to be integrated efficiently while considering data quality, metadata management and data lineage, to name a few.
A modern data architecture doesn’t rely on one data integration capability but combines several elements to deliver a breakthrough in flexibility and performance:
It is this combination of technologies, in one complete solution, that represents an entirely new paradigm in the way organizations think, manage, and work with data.
Typically, a modern data architecture can be used with a single query language such as SQL to enable speedy query response and assembly of different data models or views of the required data.
Features offered by different providers can vary and are constantly evolving, but some of the more innovative features include:
A mix of data integration approaches thus becomes crucial, spanning physical delivery to virtualized delivery, and bulk/batch movements to event-driven granular data propagation. In particular, when data is being constantly produced in massive quantities and is always in motion and constantly changing (e.g. IoT platforms and data lakes), attempts to collect all of this data are potentially neither practical nor viable. This is driving an increase in demand for connection to data, not just the collection of it.
– Gartner, Magic Quadrant for Data Integration Tools 2019

Introduced by Gartner in 2009, the Logical Data Warehouse was one of the first modern data architecture concepts that were driven by the fact that the individual data integration technologies such as data replication (ETL/ELT) and data virtualization alone could not serve all use cases.
The hybrid approach of a Logical Data Warehouse allows, to move data where necessary and to combine data without physically moving it. Thereby, it doesn’t only make data integration more efficient but also strengthens the transparency, governance, and security aspects for a compliant system. This approach enables organizations to implement flexible and sustainable data strategies for increasingly complex environments.

The most current trends such as Data Fabric, Data Mesh, Unified Data, and Analytics Platform, Data Platform, etc. continue to follow the basic idea of the Logical Data Warehouse – to replace the classic, monolithic approaches such as Data Warehouse or Data Lake by using various technologies to integrate the distributed architectures (even across clouds) to meet the modern data requirements.

To apply machine learning models on transactional and operational data, companies have to deal with huge amounts of data stored in many sources, creating a complex challenge.
Data is the main ingredient from which machine learning algorithms are trained, but traditional data warehousing systems are inefficient and difficult to scale.
They would hang up on copying and pasting the data from CSV files into a central place and format the data before building the predictive models.
Modern data architectures integrate data faster and more efficiently.
To achieve real-time functionality, companies must combine the traditional data warehouse with modern big data tools, often combining multiple technologies. Unifying these data sources into one common view provides instant access to a 360-degree view of your organization.

Customer Data Integration enables marketing operations to better understand customer and prospect behavior as singular entities.
Built well, a customer data integration platform allows organizations to centralize the data from all systems that generate touchpoints with customers and prospects, giving marketers the capability to:
A modern data architecture is the foundation for a 360 degree view on the customers.

The demand for digital transformation and increased regulatory controls have increased the need to increase revenues, cut costs and boost efficiency in an era where data is the most valuable resource in the financial sector.
Enterprises have tried to build a ‘single source of truth’ for their data using Hadoop or Data Lakes, creating even more data silos and fragmentation, leading to increased costs and inefficiencies. Modern data architectures eliminate data silos to deliver a future-proof single source of truth.
Operational and analytical data silos are combined to form a central data access layer. This access layer brings together data consumers from the business side (e.g. data analysts, data scientists) and provides much-needed data governance, data lineage, and data security.
Digitally-driven financial services organizations benefit from real-time data delivery with use cases such as real-time loan approval processes. Leveraging the modern data platform for loan approvals results in competitive advantage through faster loan approval lead times.
Utilizing a modern data platform, credit scores and pre-approval decisions can be calculated instantly with the help of procedural SQL. During customer meetings, loan applications can be directly processed online and evaluated.
Further use cases for financial services can be found here: Data Virtuality Platform enables a flexible data supply chain for financial services institutions.

Modern data platforms help healthcare providers to aggregate data from different systems for transparency and automation of workflows. That opens new possibilities for how operational teams can work with the data on the floor: use the data to track patients in real-time and better manage the patient flow.
The results are profound: reduced costs, lower staff turnover rates, and more efficient management/planning of the bed occupancy, to name a few. Furthermore, digital health and electronic health/medical records (EHR and EMR) can be enabled.

E-commerce is incredibly competitive. To get ahead of rivals, an effective data-driven decision-making capability is critical.
Leveraging data virtualization in a modern data architecture enables businesses to generate a 360° view of all data and processes by centralizing product, customer, and marketing data into a single source of truth.
It then rapidly delivers in-depth analytics that improves cross-channel attribution across all underlying data.
For example, a typical e-commerce business has:
With a modern data architecture, all these data sources can be quickly combined to deliver comprehensive views of any data related to customers, products, etc.
The simplest way to learn how Data Virtualization works is to observe a demonstration that is tailored to your precise use case.
You will learn:
Simply click below and we’ll arrange your Data Virtualization demonstration:





Data Virtuality brings enterprise data virtualization capabilities to CData, delivering highly-performant access to live data at any scale.

Discover how integrating data warehouse automation with data virtualization can lead to better managed and optimized data workflows.
Discover how our ChatGPT powered SQL AI Assistant can help Data Virtuality users boost their performance when working with data.
While caching offers certain advantages, it’s not a one-size-fits-all solution. To comprehensively meet business requirements, combining data virtualization with replication is key.
Explore the potential of Data Virtuality’s connector for Databricks, enhancing your data lakehouse experience with flexible integration.
Generative AI is an exciting new technology which is helping to democratise and accelerate data management tasks including data engineering.


